文本摘要的关键技术 - 提升信息提取效率
什么是文本摘要?
文本摘要是指从大量文本中提取出重要信息并生成简洁的总结。简单来说,就是将长篇大论变成简明扼要的内容,帮助我们快速获取所需信息。在信息爆炸的时代,文本摘要变得尤其重要,因为它能节省我们的时间,提升阅读效率。
文本摘要的两大类型
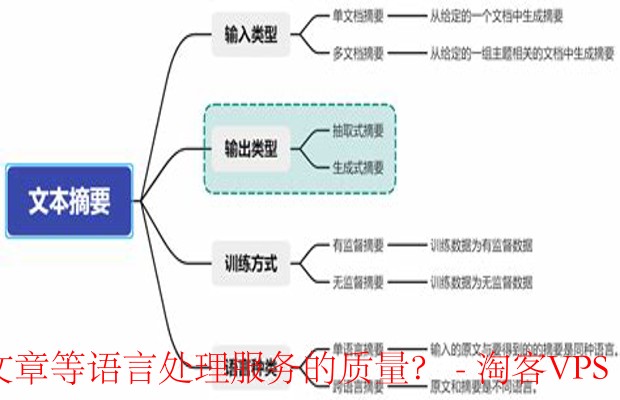
在讲述文本摘要的关键技术之前,先了解一下它的两大主要类型:抽取式摘要和生成式摘要。
抽取式摘要
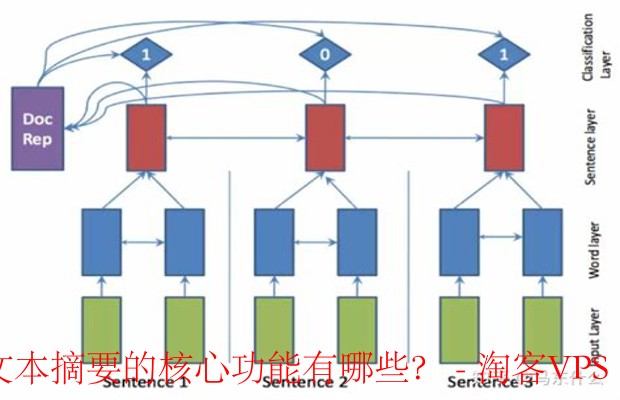
抽取式摘要的核心就是从原始文本中直接提取出重要句子或片段,合成一个简短的总结。这种方式的优势在于保留了原文的语义和上下文,但也可能导致信息的片面性。
生成式摘要
生成式摘要则使用自然语言处理技术,通过理解文本内容,重新生成概括性的内容。它更具灵活性,可以根据上下文调整表达方式,但也面临着信息失真的风险。
关键技术一:自然语言处理(NLP)
自然语言处理是文本摘要技术的基础。它涉及到对语言的理解、分析和生成。使用NLP技术,我们可以更好地识别文本中的主题、关键词和重要信息。
分词和词性标注
在进行文本摘要时,分词是第一步。有效的分词能帮助系统识别出句子中的重要词汇,而词性标注则帮助理解这些词汇在句子中的语法角色。
句子评分
抽取式摘要常常依靠句子评分算法来选择最重要的句子。常见的方法包括TF-IDF(词频-逆文档频率)和基于图的算法(如TextRank),这些方法能有效地评估句子的相对重要性。
关键技术二:深度学习

随着技术的发展,深度学习在文本摘要领域的应用越来越广泛。使用神经网络模型,特别是循环神经网络(RNN)和长短期记忆网络(LSTM),可以在生成式摘要中取得优异的效果。
Seq2Seq模型
Seq2Seq(序列到序列)模型是一种流行的生成式摘要技术。它通过将输入序列转化为固定长度的上下文向量,再生成输出序列,有效地实现了从文本到摘要的转换。
预训练模型
近年来,像BERT、GPT等预训练大模型的出现,让文本摘要的效果有了质的飞跃。这些模型通过大规模语料的学习,能理解上下文,生成更为自然和连贯的摘要。
关键技术三:文本特征提取
文本特征提取是指将文本转化为数值表示的过程。通过提取关键词、主题和情感等特征,可以帮助算法更好地理解和处理文本。
TF-IDF和词嵌入
TF-IDF是一种经典的特征提取方法,它通过计算词频和逆文档频率,为每个词分配权重。而词嵌入技术(如Word2Vec、GloVe)则将词转化为向量表示,能够更好地捕捉词之间的语义关系。
主题建模
主题建模(如LDA)可以识别文本中的潜在主题,帮助摘要生成系统理解文本的核心内容,提高摘要的准确性。
文本摘要的挑战与未来
尽管文本摘要技术已经取得了显著进展,但依然面临许多挑战,如信息的完整性、摘要的可读性和上下文的保持等。未来,随着算法的不断改进,文本摘要将会变得更加智能和高效。
人机协作
未来的文本摘要技术可能会更多地依赖于人机协作,结合机器学习的效率和人的判断力,生成更加符合用户需求的高质量摘要。
文本摘要的关键技术包括自然语言处理、深度学习和文本特征提取等。掌握这些技术,不仅能提升我们的信息获取效率,还能推动文本处理领域的进一步发展。随着技术的不断进步,文本摘要的未来将更加光明。